2025-02-10
LLM-Assisted Coding

In this blog post, I explain how I write code with the assistance of LLMs. I begin by describing use cases where I find them performing exceptionally well and others where they don't or are counterproductive. In the second part, I discuss the editor tools that I use.
Developing complex systems with LLM Copilots
In the past year, I've spent some time integrating LLMs into coding tasks, and I wanted to share a few thoughts.
About a year ago, my primary use case was enhancing my typing speed for straightforward code that I knew precisely how to write myself. I would let the model generate something acceptable, refine it manually, and add a few tests. I am currently mostly using Claude Sonnet 3.5, but I haven't noticed a significant practical difference compared to GPT-4o.
When web page lookup was introduced, I began using the chat function much more frequently to discuss various ideas and allow the model to synthesize online documentation by creating simple code snippet examples. I prefer the editor to provide the selected code and related files in the chat context rather than having to copy and paste it manually. Reasoning models like o1 or o3 assist me in understanding the trade-offs between different approaches and often highlight something I am unaware of. In the next section, I'll discuss how to learn effectively.
Great for learning
When learning a new programming language or framework, it's highly beneficial to ask numerous questions. For instance, I recently developed a Raft implementation in Rust, and I was able to learn asynchronous patterns, concurrency primitives, and futures in just a few hours. While learning, I find it valuable to write simple snippets and allow the model to refine them until they compile and pass the tests, asking many questions along the way.
Learning by doing, guided by an infinitely patient LLM instructor, is far more effective for me than reading a blog, documentation, or watching a video. It keeps me highly engaged and is intellectually stimulating. I primarily use inline code completion in the initial phase, followed by assisted refactoring. For this purpose, it's essential that the editor responds promptly to maintain focus.
Bad when I need strongly opinionated feedback
I find models quite poor at offering strong opinions and challenging incomplete or vague questions. When I'm exploring new problems or libraries, I need to learn the terminology to ask precise questions. Models sometimes focus too much on the specific question asked, rather than my intent. Sometimes they even fabricate a plausible API that doesn't exist to avoid admitting that the approach doesn't make sense. It requires a bit of patience to craft a prompt that encourages them to be less condescendingly and behave like a teacher.
LLMs are particularly poor at designing new architectures. For example, I was recently researching and prototyping modern solutions for frontend state management. It's easy for the model to list all the libraries and write simple examples. However, it is much more challenging to discuss trade-offs when integrating them into a pre-existing legacy architecture that is unlike anything it has seen before. It seems to lack the intuition of a good senior software engineer, no matter how detailed my explanation is in the prompt.
Lower intellectual stimulation
This is the primary drawback to using LLMs for coding that I've discovered so far. I believe they reduce the intellectual stimulation of problem-solving.
I sometimes find myself unnecessarily delegating tasks that are slightly uncomfortable, where I would otherwise need to think or occasionally sketch on paper, like writing a complex boolean condition or calculating the index of an element in a multidimensional array. This occurs because many of the tools I use automatically complete code for me by default.
Removing these small yet frequent intellectual challenges diminishes the satisfaction of completing a coding task, turning it into almost a chore, a box to tick. Another, even more subtle issue is that often the automated implementation is just wrong enough to be difficult to detect. Since I didn't feel like writing it, I probably don't feel like thinking too hard about it either. LLMs frequently overlook edge cases, make off-by-one errors, or call the wrong function with a similar name, just to name a few.
Having intricate sections of the code written by the model and only summarily reviewed introduces black-box code, which I believe is a significant concern in assisted software development. There are a few mitigations. We should pay very close attention to what the model produces and potentially rewrite the most complex or confusing parts. Additionally, we should write and maintain highly comprehensive tests.
Let's now discuss a couple of tools I'm using: GitHub Copilot and Cursor. Note that these tools are advancing rapidly, and the next section will likely become outdated soon.
Github CoPilot
It is a VSCode extension. I find it somewhat cumbersome to use. It's rather slow in generating code, especially if the module is large. It requires manually adding all the files we want to edit and lacks good discovery capabilities. The model selection is also somewhat limited, but as mentioned before, I don't notice a significant performance difference between them, so it's not a dealbreaker.
I believe it's a promising first step into LLM-assisted coding because it includes fundamental features like chat and code composition.
Cursor Editor
The Cursor team decided to fork VSCode and develop features that are not feasible with an extension. Essentially, it's a lot of enhanced UX built on top of various models.
What I like
I really appreciate the UX quality-of-life enhancements, such as checking the interface of a function I'm calling and performing light data manipulation on the inputs. I frequently use CMD+K and TAB-to-complete. It also retains in memory the last few lines of code I wrote, so while I'm navigating between files, the completions are relevant to the task I'm working on; for example, it suggests calling the function I just wrote in another module.
I appreciate the automatic discovery of relevant files through RAG. It significantly accelerates communication, eliminating the need for extensive code copying and pasting. It automatically ingests syntax errors generated by the language server. Furthermore, it also selects the files to include in the changes, although in large codebases, I still find it somewhat imprecise.
Lastly, I appreciate the ability to look up documentation online and access public API suggestions with references. I want to learn how to leverage this even further.
What I don't like
I don't like the idea of using a paid editor that could one day diverge significantly from the standard VSCode. The editor is such a fundamental part of my development workflow: I spend a lot of time customizing settings and building muscle memory around keyboard shortcuts. I would hate to become overly reliant on features I need to pay indefinitely to feel like a productive developer. The reason I even considered switching to Cursor is that it is fully compatible with VSCode; all my extensions work seamlessly, and there's no hidden cost for reverting back.
I noticed few UI small annoyances: there was a bug with the autocompletion window being stuck on the top and not being able to move it. Since it's only sporadically rebased on top of VSCode, means it doesn't contain the latest features. Maybe not a big practical issue, but it may prevent to use the latest version of certain extensions.
Lastly, I attempted the agent mode on a simple task: I aimed to eliminate the redundant function exports in a TypeScript project using ts-prune and having the agent edit a few files at a time. I couldn't keep it focused on the task. It only waits for 10 seconds of shell command execution before terminating the process, and when it makes edits, it renames modules and functions instead of merely removing the export keyword. I find it quite unreliable for now, but I'm confident it will improve quickly.
Opportunities: what I think will improve soon
There is a significant amount of research on how to alter the "personality" of models after training. I'm confident it will be possible to develop much more opinionated models that are specialized for coding. I find that reasoning models like o1 and o3 grasp more nuances of the questions by contemplating them a bit before attempting to answer, compared to, say, GPT4o, which tries to provide a zero-shot answer to the exact question asked.
The speed of code generation is currently suboptimal. It sometimes takes a considerable amount of time to generate code, leading me to choose to write it myself. I anticipate that this will continue to improve rapidly.
The developer tool ecosystem will also learn to better utilize LLMs; for example, the highly detailed Rust compiler errors have an advantage compared to the concise TypeScript errors.
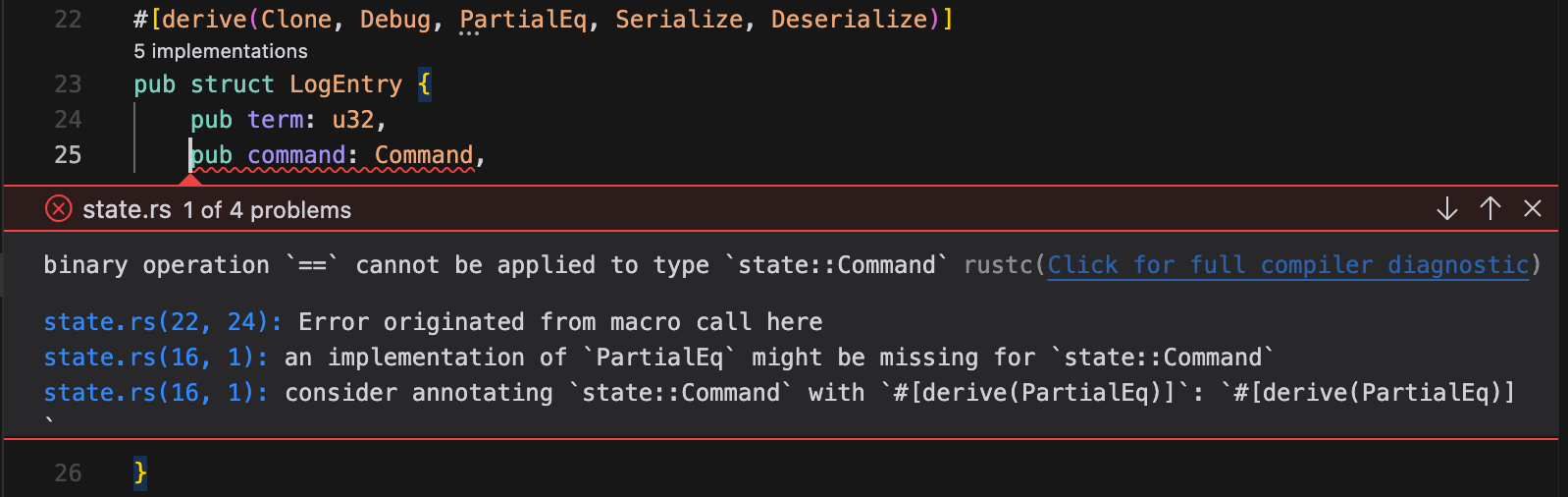 Rust errors are verbose and contain suggestions that the model can use to fix the error
Rust errors are verbose and contain suggestions that the model can use to fix the error
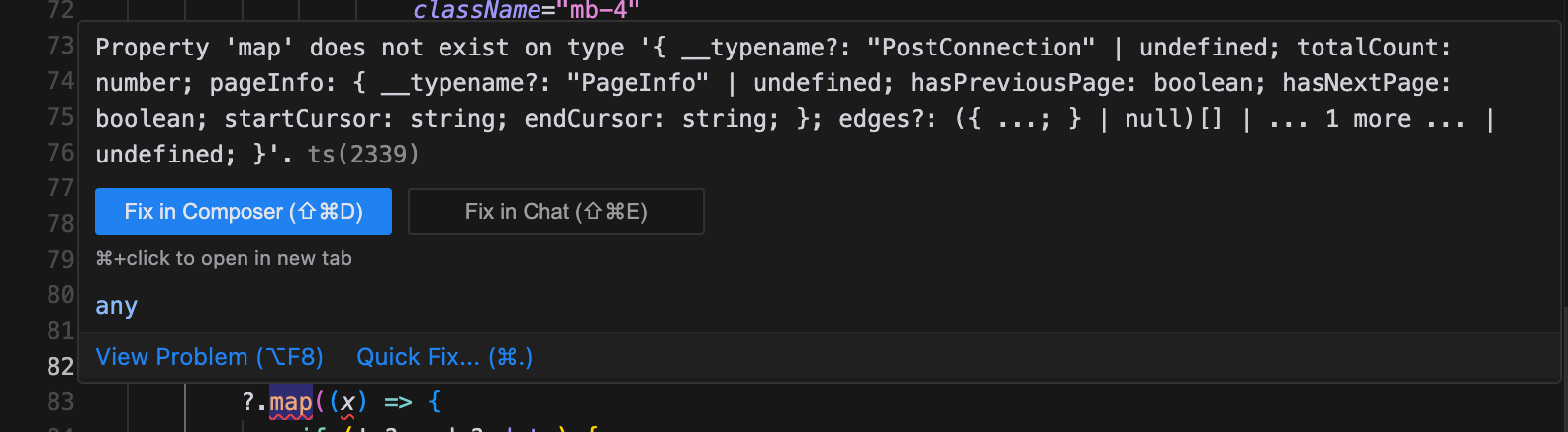 Typescript errors are truncated and don't contain suggestions
Typescript errors are truncated and don't contain suggestions
The code editor might become a commodity once the developer community agrees on a set of essential features. At present, nothing in Cursor appears too challenging to implement directly within VSCode.
Conclusions
In this article, I shared some reflections on assisted coding. I'm quite optimistic about the technology progressing swiftly in the near future, and I suggest experimenting with various tools to comprehend the usability trade-offs. Copilot and Cursor are excellent starting points.
Consider how reduced intellectual stimulation and black-box code could impact the quality of your work and determine how to mitigate these effects. Leverage LLM assistance and its limitless patience for learning concepts while coding, rather than relying on blog posts or documentation.
In the near future, I will explore tools for reviewing pull requests, automated test creation, and straightforward feature autonomous implementation.